
This is my customary update of percentage of deep-learning papers in the major vision conferences. At CVPR 2015, I described its exponential growth, and after ICCV 2015 I wondered whether it had plateaued.
Since the CVF has not released the papers yet, I had to adapt my script to take the titles from the program.
[UPDATE] CVF papers are online, so we can use the generic script shown below.
You can download all titles in TXT format in here if you want to play around. Here the evolution of the results:
CVPR2013: 0.85% ( 4 out of 471)
ICCV2013: 1.54% ( 7 out of 455)
CVPR2014: 3.70% ( 20 out of 540)
CVPR2015: 14.45% ( 87 out of 602)
ICCV2015: 14.45% ( 76 out of 526)
CVPR2016: 23.48% (151 out of 643)And the plot using XKCD style, as described in this blog post:
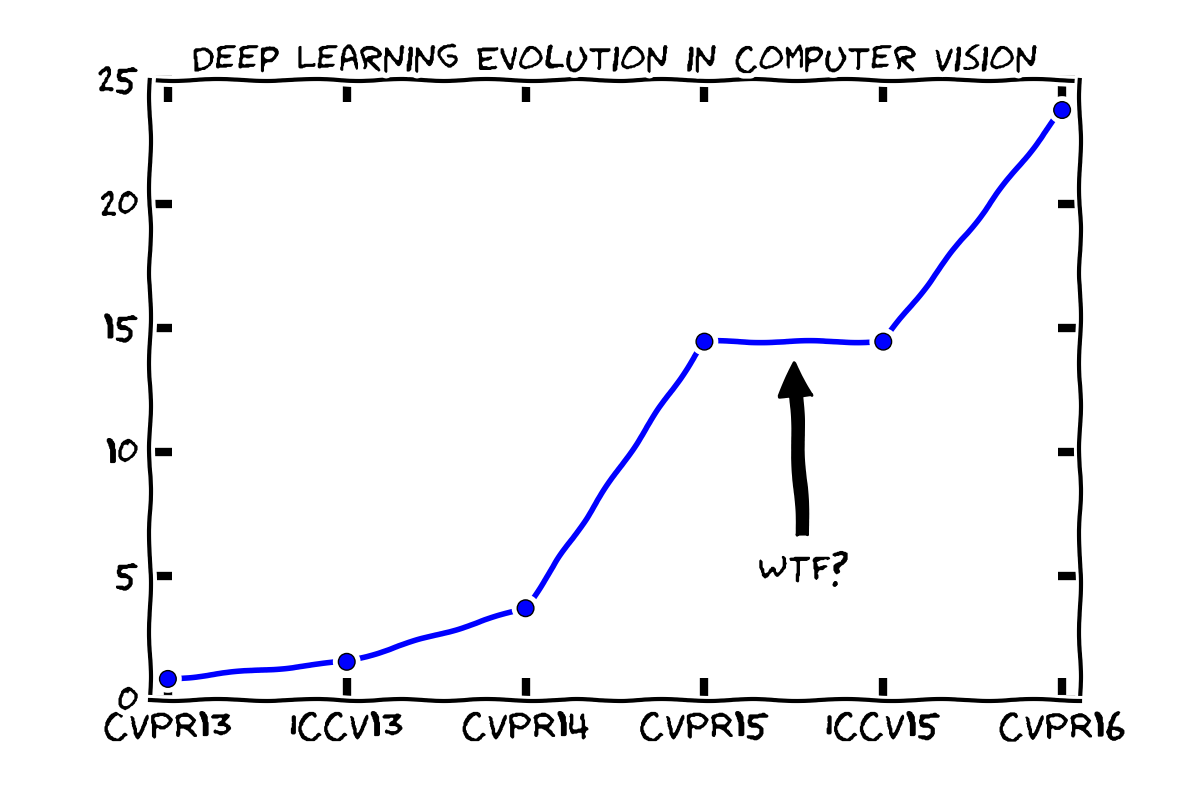
So the plateau was in fact only a short pit stop to take over again. Maybe it saturated in the classical areas such as object detection or image labeling and is now expanding to the rest of the topics?
Here the updated code for you to try:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
from lxml import html
conferences = ["CVPR2013","ICCV2013","CVPR2014","CVPR2015","ICCV2015","CVPR2016"]
for conf in conferences:
# Get the HTML text and find the classes of type 'ptitle'
response = requests.get("http://www.cv-foundation.org/openaccess/"+conf+".py")
tree = html.fromstring(response.text)
papers = tree.find_class('ptitle')
# Get all titles in a list
all_titles = []
for paper in papers:
title = paper.xpath('a/text()')
all_titles.append(title[0])
# Search for the 'deep'-inducing keywords
keywords = ['deep', 'cnn', 'convolutional', 'neural network']
count = 0
for title in all_titles:
for kword in keywords:
if title.lower().find(kword)>=0:
count = count+1
break
percent = count/float(len(all_titles))*100
print("%s: %.2f%% (%d out of %d)" % (conf, percent, count, len(all_titles)))And here the old code to parse it from the program:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from HTMLParser import HTMLParser
# Global variables
on_strong_tag = 0;
all_titles = [];
# Create a subclass of HTMLParser and override the handler methods
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
global on_strong_tag
if tag=='strong':
on_strong_tag = 1
def handle_endtag(self, tag):
global on_strong_tag
if tag=='strong':
on_strong_tag = 0
def handle_data(self, data):
global on_strong_tag, all_titles
if on_strong_tag == 1:
all_titles.append(data);
# Parse the file (I erased the orals and spotlights,
# and removed all '#&' and '&')
parser = MyHTMLParser()
f = open('cvpr2016.html', 'r');
parser.feed(f.read())
# Search for the 'deep'-inducing keywords
conf = 'CVPR2016'
keywords = ['deep', 'cnn', 'convolutional', 'neural network']
count = 0
for title in all_titles:
for kword in keywords:
if title.lower().find(kword)>=0:
count = count+1
break
percent = count/float(len(all_titles))*100
print("%s: %.2f%% (%d out of %d)" % (conf, percent, count, len(all_titles)))